'echo' echoes a text to the screen?
birot@garmur:~ > echo hi, I am the teacher!'cat' (con)catenates files (links them together, as a chain), and prints them on the screen
hi, I am the teacher!What is this useful for???
cat file1 [file2...]
"Pager" programs: the first one used to be 'pg' ...
'more' Prints the given file to the screen, page after page (Space: next page; Enter: next line; q = quit more; ? or h: help ==> check it for more help!)
'less'
Similar to 'more' but knowing... even more. It is easier to move backwards,
and based on 'more' and 'vi'.
What is 'echo' useful for? And what have we been doing with 'cat' so far?
The manual of 'cat':
DESCRIPTIONWhat is that?
Concatenate FILE(s), or standard input, to standard output.
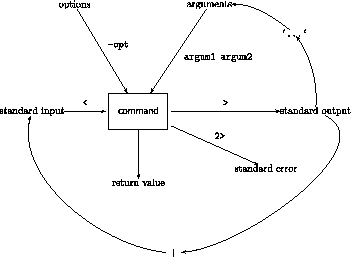
Remember, in UNIX everything is file... Even the screen and the keyboard! So in fact 'echo' puts a text into an output file, and if no file is specified, this file is the so-called "standard output', that is the screen. Similarly, 'cat' puts the concatenation of the input files into an output file. If no input file is specified, then this is the "standard input", that is the keyboard. And if no output is specified, this is the standard output, the screen.
In fact, each command has one input (standard input) and 2+1 outputs (standard output, standard error + return value). Usually if the return value is 0, it means that the command has run successfully.
Redirection of the input and output into files:
< the input is taken from the specified file
> the output goes to the specified file (if it already exists then it is overwritten, the previous content is lost)
>> the output goes to the specified file, but if it already exists then the output is appended to its previous content
| pipe: the output of the previous command is used as the input of the next one
`...` the expression is replaced by the output of the command line appearing between the back quotation marks (very useful when you want turn the output of a command or a pipe-line into the argument of another command)
2> redirects the standard error in bash shell (in other types of shell there may be other ways to do that)
Now we understand what does 'cat file_name' and 'cat
> 'file_name'.
Examples:
echo hello! how are you? > welcometty print the file name of the terminal connected to standard input.ls -l ../Mail >> list_of_mails
ls | cat (What is the difference between this and writing simply 'ls'???)
echo Hi! " " Hi again! > /dev/tty/3
tee read from standard input and write both to standard output and to files: like a "T-joint" in a plumbing installation
Example:
cal 2002 | tee calendar2002 my_calendar | moreCombining more commands into one line: ( ; ):
(ls ; ls ..) > directory
Information can enter a command either through standard input (keyboard by default; or file if you redirect it using <) or through its arguments (and options). Information comes out from a command through standard output (screen by default; or file if you redirect it using >), standard error (screen by default; or file if you redirect it using 2>), and the return value. Use a pipe line (|) to redirect the standard output of a command to the standard input of another command. Use back quotation marks (`...`: in the upper left corner of most keyboards) to redirect the standard output of a command to the argument of another command.
Note that there are basically three kinds of commands:
Introductory remark: a file in Unix should be seen as a sequence of lines, each of them being a sequence of characters, ending with an end-of-line signal.
(Check always the manual for more options...)
(Pay attention: file names are sometimes to be put as part of the argument
list, but in other cases they are the input, therefore < should be used.)
head
outputs the first part of a file (first 10 line by default)
head -c N prints the first N bytes
head -n N gives the first N lines
tail
outputs the last part of a file (first 10 line by default)
tail -c N prints the last N bytes
tail -n N gives the last N lines
rev reverses the lines of a file: The rev utility copies the specified files to the standard output, reversing the order of characters in every line. If no files are specified, the standard input is read.
tr translates / transforms a file (st. input to st. output) by translating, squeezing or deleting characters
tr -d [set] : deletes all the tokens of these characters
tr [set1] [set2] : replaces all the tokens of the i-th element of
set1 with the i-th element of set2.
e.g. tr [1-9] [a-i]
tr -s [set1] [set2] : squeezes all repetitions of characters in
set1 (in set2, if -d is present) into a single character.
e.g. tr -s [\ ]
: all sequences of spaces are condensed into a single space
tr -d -c [0-9] : remove all non-numerical characters (-c : complement
of set1)
wc Prints line, word, and byte counts for each FILE, and a total line if more than one FILE is specified. With no FILE, or when FILE is -, reads standard input.
-c
print the byte counts (compare with the file size given by 'ls -l' !)
-m
print the character counts
-l
print the newline counts
-L
print the length of the longest line
-w
print the word counts
sort Write sorted concatenation of all FILE(s) to standard output.
-b
ignore leading blanks in sort fields or keys
-d
consider only blanks and alphanumeric characters in keys (by sorting)
-f
fold lower case to upper case characters in keys
-r
reverse the result of comparisons
+N shift
N columns when sorting, i.e. sort according to the N+0-th column.
uniq Looks
for repeating lines (next to each other!) and is able to manipulate them.
If no option is given, then it removes the duplicate lines from a sorted
file: discards all but one of successive identical
lines from INPUT (or standard input), writing to OUTPUT (or standard
output).
-c
puts a prefix before each line, giving the number of occurrences
-d
outputs only the self repeating lines, each of them only ones
-u
outputs only the NON self repeating lines
Examples:
In order to make easy calculations you can use the 'bc' command (bell's calculator). Type bc <RETURN> and you can immediately type in any expressions, like 3+4 or (45/3400)*100. In fact, similarly to the way we were writing short files by using 'cat', we are just using the fact that this command needs an input file, and if nothing else is specified, then it is the standard input. Therefore the program can be ended by ^d (CTRL + D: end-of-file). Or, alternatively, by ^c (CTRL + C: stop the running program).
Therefore why not doing things like:
echo 3+4 | bcHey! Why is 23 / 46 = 0 ?! Because, if otherwise not specified, bc works with integers. Type ' scale = 4 ' to be able to receive your results with four decimals.
echo 23/46 | bc
(echo scale = 4; echo 5/8) | bcWhat does
echo 13 % 3 | bcmean? The remainder of the division. And what is the problem with this one:
echo (13/26)*4 | bcTry rather
echo \(13/26\)*4 | bc... and remember how you have to escape metacharacters!
(From Henny's
page.)
1. Het nut van woordenlijsten
Je kunt van een of meer teksten een alfabetische woordenlijst maken, of een frequentielijst: hoe vaak komt elk woord voor?
Een woordenlijst (unieke woorden) geeft het vocabulaire
weer (interessant bij b.v. kindertaal, speciale talen). In
principe geldt: hoe meer tekst je ter beschikking hebt,
hoe groter vocabulaire, maar die toename wordt natuurlijk steeds
minder, en bij b.v. een programmeertaal heb je alle mogelijke
'woorden' al heel snel binnen.
Bij kindertaal onderzoek wordt de type/token ratio gebruikt:
aantal verschillende woorden gedeeld door totaal aantal
woorden. De lengte van de tekst speelt ook een rol:
Hoe groot is
type/token ratio bij een tekst van 2 woorden?
Als je 6 romans
van Vestdijk neemt en er nog 6 bijdoet, wat gebeurt er dan met je type-token
ratio?
Daarom wordt type-token ratio meestal genormaliseerd
door in tekststukken van vaste lengte te tellen, bv steeds 1000
woorden en de gevonden ratio's te middelen.
Een woordenlijst met woordfrequenties erbij is
o.m. nuttig voor taalonderwijs, en voor het opzetten van
taalexperimenten (weten wat frequent gebruikte
woorden zijn), voor tekstanalyses: wat zijn woorden specifiek voor
deze auteur of deze tekst? CELEX is een database
met allerlei gegevens over Nederlandse woorden, o.a.
frequentiegegevens.
2. Hoe maak je een woordenlijst?
Je wilt een tekst in woorden splitsen en die gesorteerd
onder elkaar zetten, of ze tellen en op frequentie sorteren. Als
je een tekst in woorden wilt splitsen moet je een
aantal beslissingen nemen: zijn getallen ook woorden? Is er een
verschil tussen Kok en kok? We houden het even
simpel: getallen tellen niet mee, en we maken geen onderscheid
tussen hoofd- en kleine letters. Bij het splitsen
zelf duikt een probleem op: tussen woorden staan spaties, maar hoe
krijg ik de leestekens weg? Het volgende programmaatje
neemt dit alle voor zijn rekening:
3. tr (translate/transform)
Transformeert 1 karakter (!!) in een ander karakter,
je kunt wel een reeks wijzigingen tegelijk opgeven, maar geen
combinaties van letters zoeken en vervangen.
Als je een tr commando op een flinke file toepast,
zie je vaak beter of je aan alles gedacht hebt, maar als je een
speciale opdracht even uit wilt testen (zoals in
de eerste 2 opdrachten) kun je ook direct vanaf de terminal werken:
tr string1
string2
zet
je tekst
veranderde
tekst verschijnt
zet je
tekst
veranderde
tekst verschijnt
totdat je met Ctr-D of Ctr-C het programma tr weer
verlaat
Als voorbeeldmateriaal in het practicum gebruiken
we de teksten in directory /users1/vannoord/Federalist. Voor
achtergrond informatie over deze teksten, zie George
Wellings' imposante USA project,
meer in het bijzonder deze
bladzijde.
Basis syntax tr: tr string1 string2 <file1 . Voorbeelden:
tr e q < fed1.txt
tr eE qQ < fed1.txt | less
redirection
van standard input, standard output; pipes.
onderscheid
hoofdletter / kleine letter van belang
tr aeiou qqqqq < fed1.txt | less
tr A-Z a-z < fed1.txt > myfed1.txt
tr aeiou [q*5] < fed1.txt | less
tr aeiou [q*] < fed1.txt | less
tr ' ' '\012' < fed1.txt | less
tr ' ' '\n' < fed1.txt | less
De laatste
twee commando's vervangen een spatie door een newline. ASCII tekens kun
je aangeven via hun
nummer, hier
\012, zie man ascii; sommige tekens kun je aanduiden via speciale karakters,
zoals \n, \t (tab). De
backslash
is een zgn. Escape-karakter, dat aangeeft dat het teken erachter een bijzondere
betekenis heeft.
Quotes zijn
soms nodig bij vreemde tekens.
Opties van tr:
-s (squeeze) perst aantal dezelfde tekens samen
-d (delete) verwijdert tekens
-c (complement) neemt alle tekens die NIET in string
1 voorkomen.
tr -s ' ' '\012' < fed1.txt | less
tr -d '.' < fed1.txt | less
tr -c aeiou [q*] < fed1.txt | less
tr A-Z a-z < fed1.txt | tr -cs a-z '[\012*]' > fed1.txt
let op: ook
hier is * noodzakelijk!
De laatste opdracht is het begin van ons woordenlijstprogramma:
het leest fed1.txt, verandert eerst hoofdletters in
kleine letters, verandert vervolgens alle tekens
die geen kleine letter zijn (-c a-z: dit betreft dus cijfers, spaties,
leestekens en newlines!) in een newline karakter
\012, waarbij -s zorgt dat meerdere van die tekens samengenomen
worden (niet meer dan 1 newline achter elkaar),
en schrijft het resultaat, een lijst van alle woorden, in volgorde van
de
tekst, naar een nieuwe file.
4. Woordenlijst
1.programma 1: plaats ieder woord op een eigen regel:
tr (zie boven)
2.programma 2: sorteer regels (en geef alleen unieke woorden)
sort (-u)
met sort -u krijg je een alfabetische lijst unieke woorden
3.programma 3: geef unieke woorden in reeds gesorteerde lijst waar nog dubbelen in zitten (en tel ze)
uniq (-c)
met de opeenvolging sort|uniq -c krijg je een lijst unieke woorden met hun frequentie ervoor: een frequentielijst
4.programma 4: sorteer de woordenlijst met frequenties ervoor, hoogste aantal boven:
sort -nr
sorteer numeriek
-n, anders krijg je de 'alfabetische' volgorde van de cijfers, b.v. 10,
100, 2 en reverse -r, dat wil
zeggen met
het hoogste getal bovenaan
Gebruik de UNIX pipe om de 4 commando's te combineren.